PokéSynth explores the intersection of generative AI and creature design through a Convolutional Variational Autoencoder that learns to synthesize novel Pokémon characters. Working with Kshitij Sawant and under the guidance of Dr. Francesco Fedele, we developed a framework to understand perceptual quality and novelty in AI-generated creature designs, training our model on over 800 existing Pokémon to capture the complex visual features that define this iconic franchise.

Motivations, from Left to Right: Exquisite Corpse, Poster of Movie Yōkai Monsters: 100 Monsters (1968), Mona Lisa w/Deep Dream Effect
Creature design exists at a unique intersection of illustration, taxonomy, cultural mythology, and generative methods. Our project positions itself within a century-long trajectory of hybrid creature-making, drawing on three key historical precedents. The Surrealist practice of Exquisite Corpse introduced collaborative, sequential methods for creating unexpected hybrid forms, which is a direct precursor to AI-human co-creation. Japanese Yōkai and other folkloric traditions established the cultural practice of assembling creatures from modular parts, forming a visual language that would later influence Pokémon design. Contemporary digital systems like GANs, DeepDream, and ArtBreeder continue this logic through algorithmic hybridization, positioning machines as creative collaborators rather than mere tools.
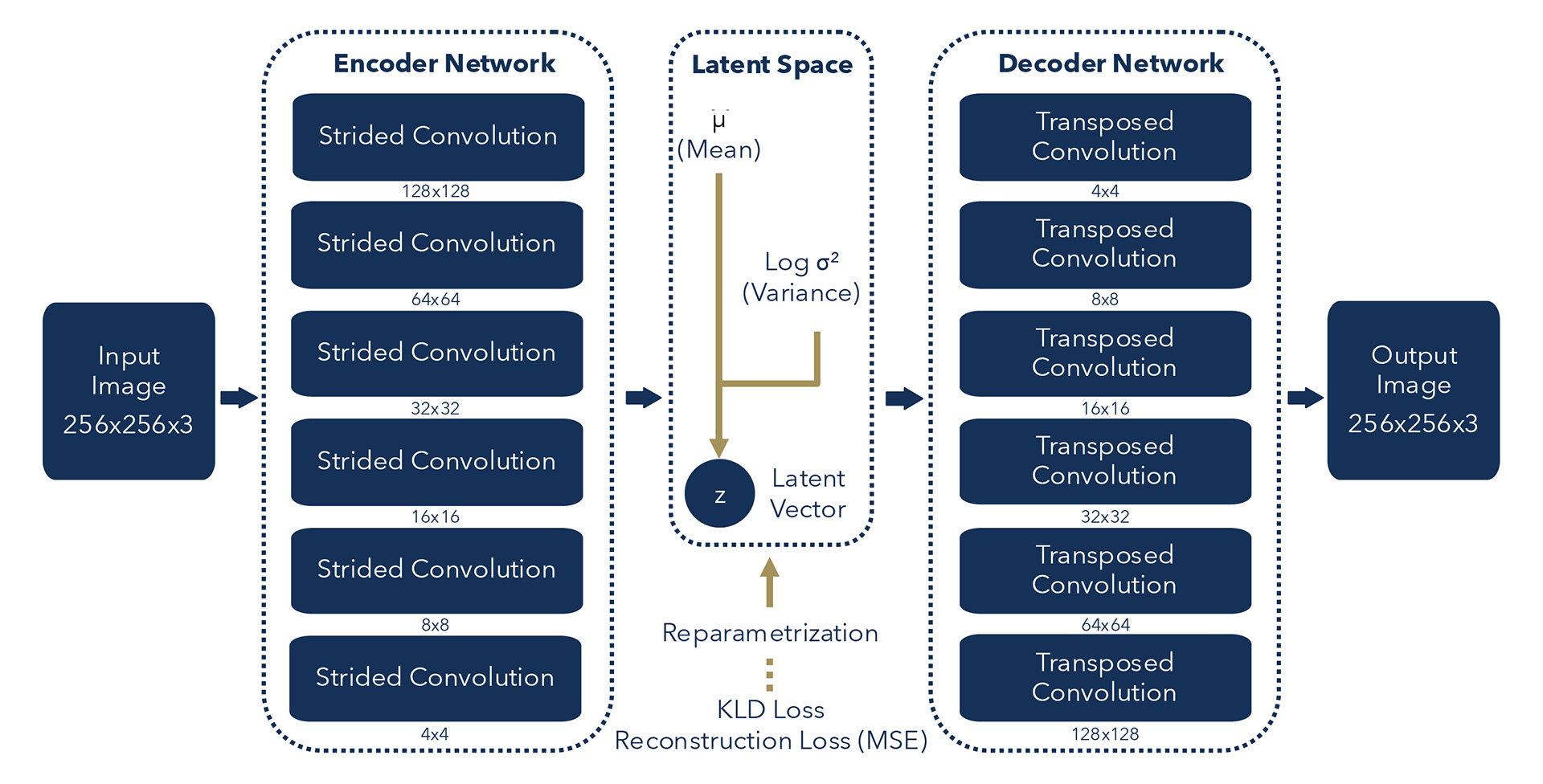
Schematic Diagram of Convolutional Variational Auto Encoder (C-VAE) for Image Processing
The core of PokéSynth is a symmetric Encoder-Decoder architecture that processes 256x256-pixel images using strided and transposed convolutions. The Encoder maps input images to a 128-dimensional latent space, learning the parameters of a Gaussian distribution that captures the essential features of Pokémon design. During training, the model balances two competing objectives: a reconstruction loss using Mean Squared Error maintains pixel-level fidelity, while Kullback-Leibler Divergence regularizes the latent distribution toward a standard Gaussian. The reparameterization trick enables gradients to flow through the stochastic sampling process, making the entire system trainable end-to-end.
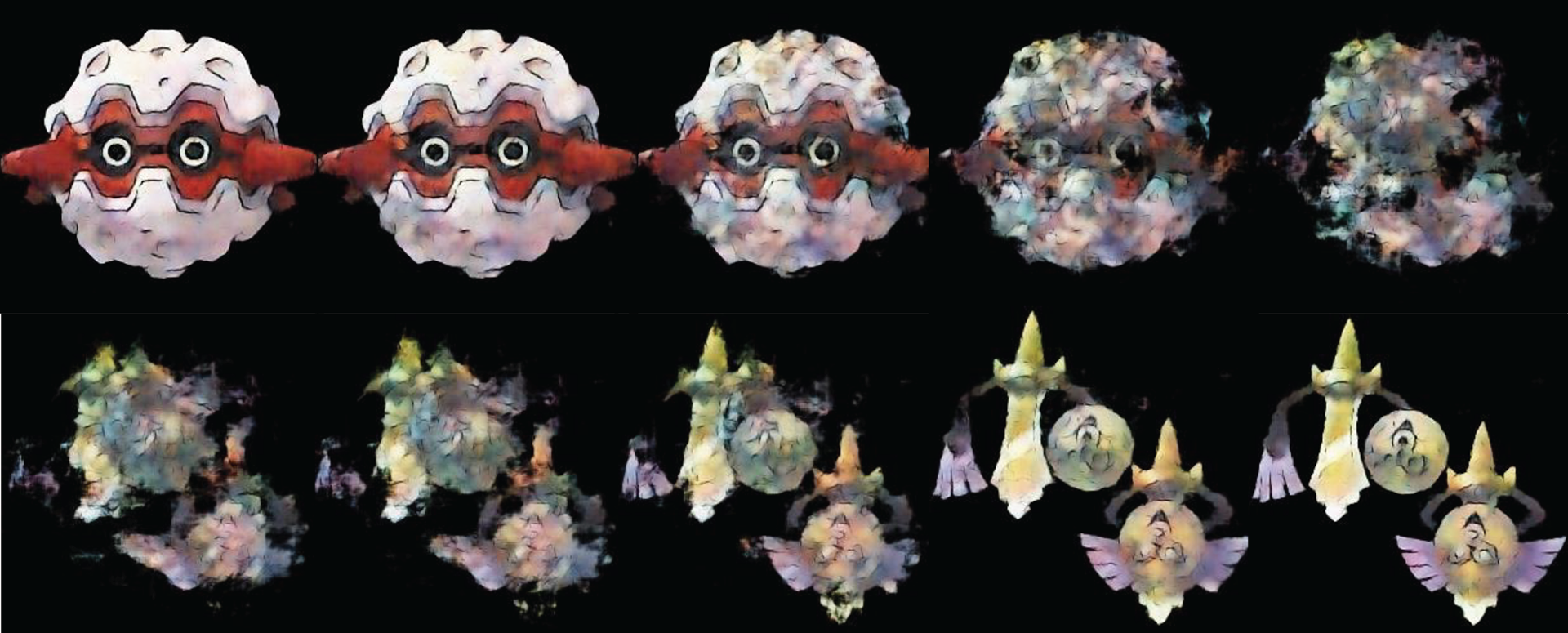
The Reparameterization tools are used during training to allow gradients to flow through the stochastic sampling process, ensuring the model is trainable.
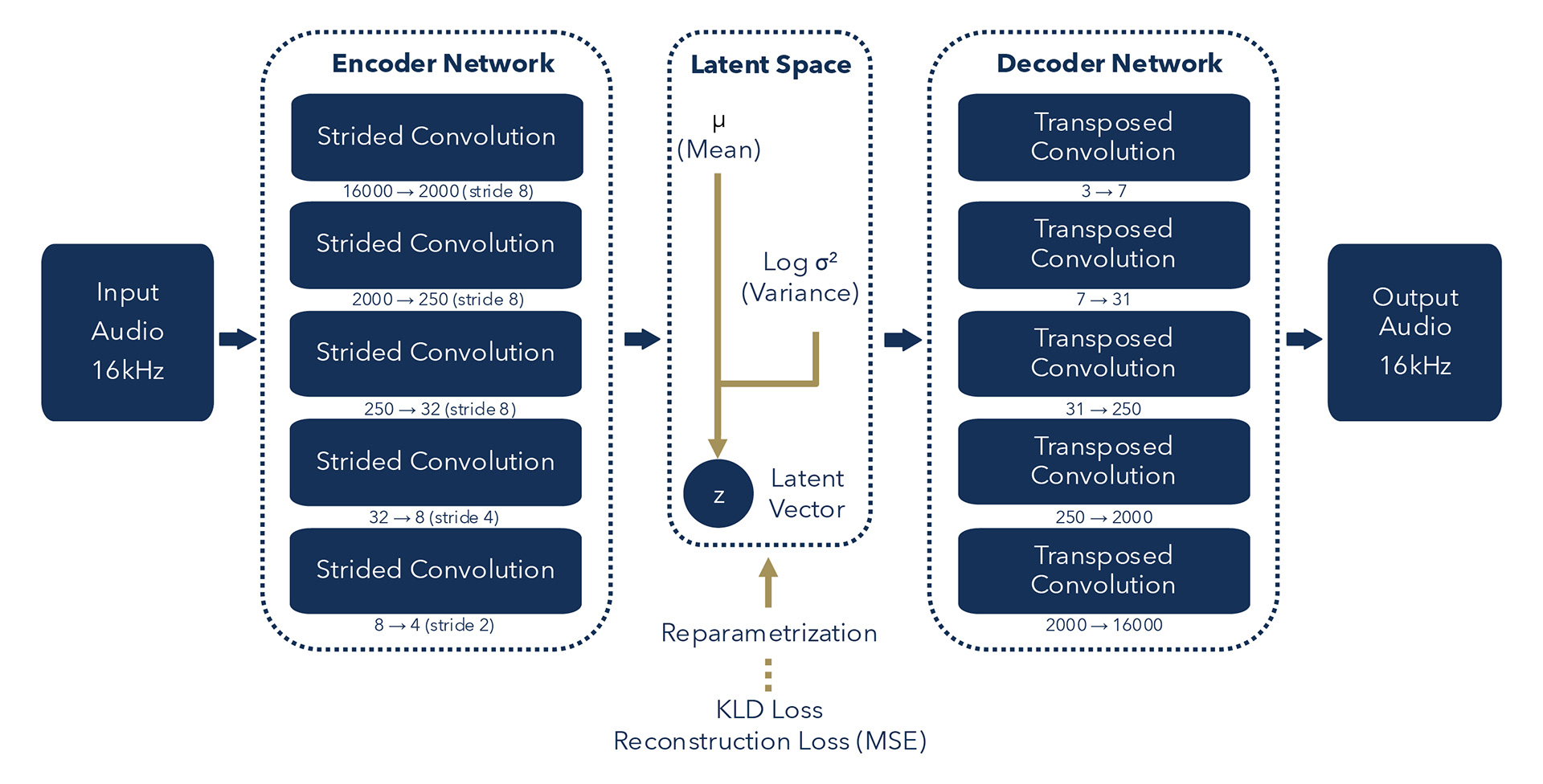
Schematic Diagram of Convolutional Variational Auto Encoder (C-VAE) for Audio Processing
The VAE processes audio through a compression-reconstruction pipeline where Pokémon cry waveforms (mono audio at 16kHz, 16000 samples) are first encoded using a series of 1D convolutions that progressively downsample from 16000 samples down to just 3 time steps across 256 channels, resulting in 768 flattened dimensions that are then mapped to a 64-dimensional latent distribution (mean and log variance). This compact audio latent code is concatenated with the 128-dimensional image latent code and passed through a fully connected layer to produce a unified 256-dimensional combined latent representation, in which the model learns to associate visual Pokémon features with their corresponding cries. The decoder then reverses this process, mapping the combined latent back to 768 dimensions, reshaping to [batch, 256, 3], and using transposed convolutions to upsample back to the original 16000-sample waveform. Key design choices include preprocessing audio to zero mean and unit variance, using 1D convolutions to capture temporal patterns, employing a 64-dimensional bottleneck to force efficient representations, and creating a shared latent space that enables the model to learn cross-modal relationships between how Pokémon look and sound.










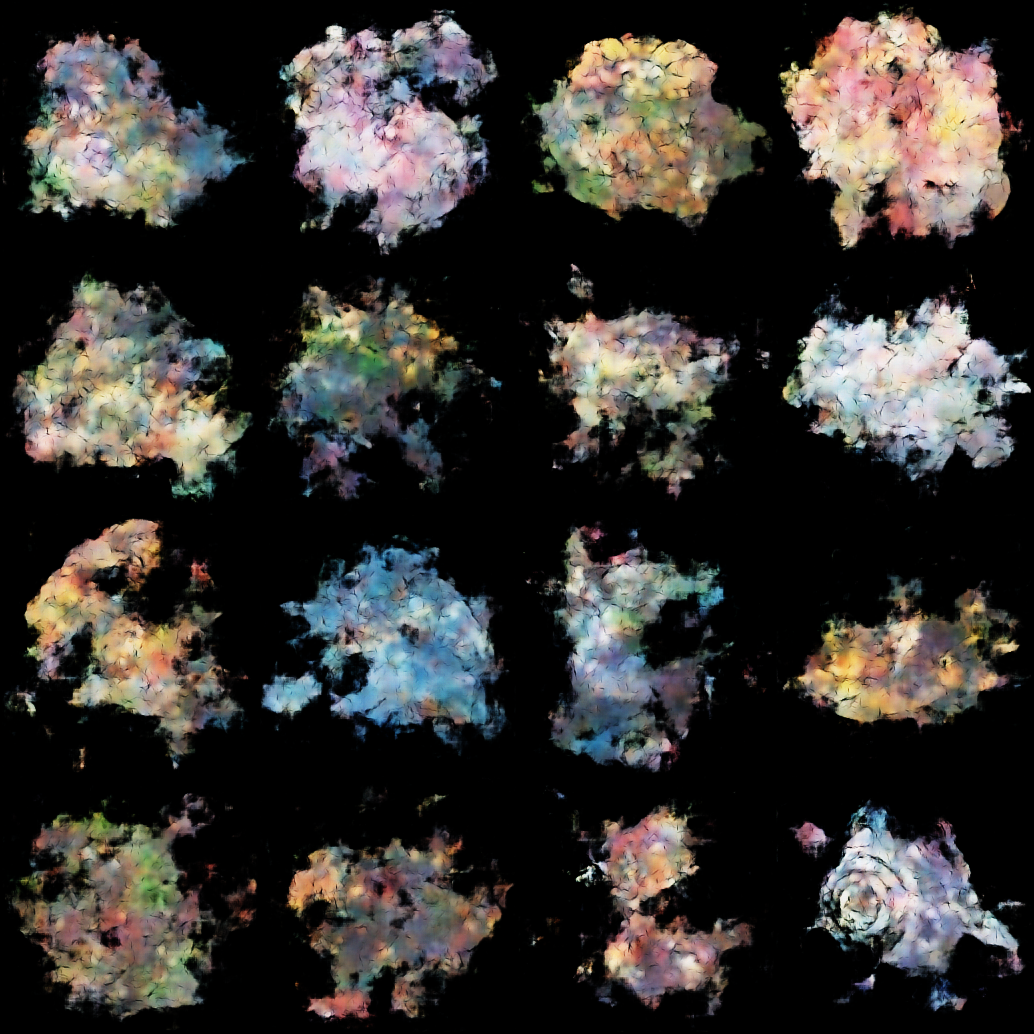
The VAE successfully captured the complex visual features that define Pokémon designs, demonstrating the viability of generative models for data-driven creative asset development. The learned latent space enables smooth interpolation between existing creatures and the generation of entirely novel designs that retain the franchise's characteristic aesthetic.
We also explored multimodal generation by jointly learning visual and audio representations (Pokémon cries), though the audio outputs proved too noisy for practical use, posing an interesting challenge in cross-modal synthesis.
Looking forward, we envision expanding PokéSynth into a true multimodal system that jointly learns latent representations for both visual appearance and sound. By applying classifiers to the latent space, we could enable controllable generation where users specify desired types (Fire, Water, Grass) or feature sets, creating an interactive tool for game designers and artists. This work opens questions about how AI systems can serve as creative collaborators in entertainment and game design, while respecting the cultural and aesthetic traditions that inform creature design across different media.