This project explores facial micro-expressions as an embodied, affective interface for real-time audiovisual synthesis. Using computer vision and audio signal analysis, the system captures involuntary expressive reactions—commonly referred to as “stankface”—and translates them into continuous control signals for sound synthesis and visual modulation. Rather than relying on explicit gestural input, the system treats subtle facial responses as implicit emotional feedback, allowing the performer’s visceral reaction to music to become part of the compositional loop.
At the core of the system is a facial analysis pipeline built with MediaPipe Face Mesh. High-resolution facial landmarks are extracted in real time and normalized relative to overall face dimensions to ensure robustness across different users and camera positions. From these landmarks, a composite “stankface index” is computed using multiple micro-expression features, including nose compression, lip ovalness, eyebrow contraction, mouth narrowing, eye squinting, and cheek elevation. Each feature is weighted and combined into a single continuous parameter, which is then adaptively normalized over time to expand the expressive range and accommodate individual facial habits.
The “Stank Index” is computed using real-time facial analysis from MediaPipe FaceMesh, which provides a dense set of facial landmarks for each video frame. The system models the stankface as a combination of micro-gestural features associated with intense musical affect, including nose wrinkling, lip deformation, eyebrow contraction, eye squinting, mouth narrowing, and cheek raising. Each feature is calculated from geometric relationships between selected landmark pairs (such as eyebrow distance or nose compression) and normalized by an estimated face size derived from facial boundary landmarks. This normalization ensures scale invariance across different faces, camera distances, and lighting conditions.
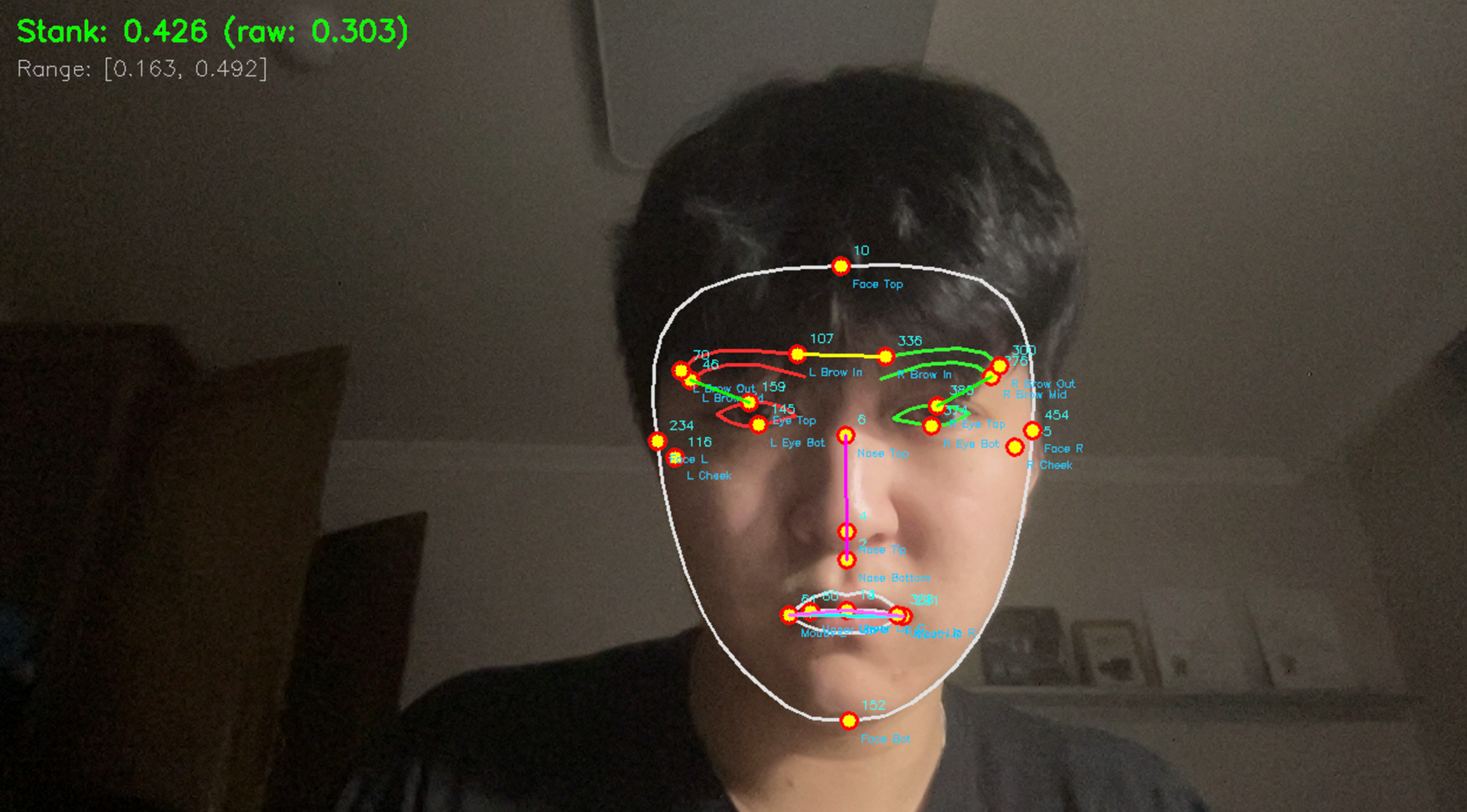
Facial Expression no. 1: Stank Index=0.426
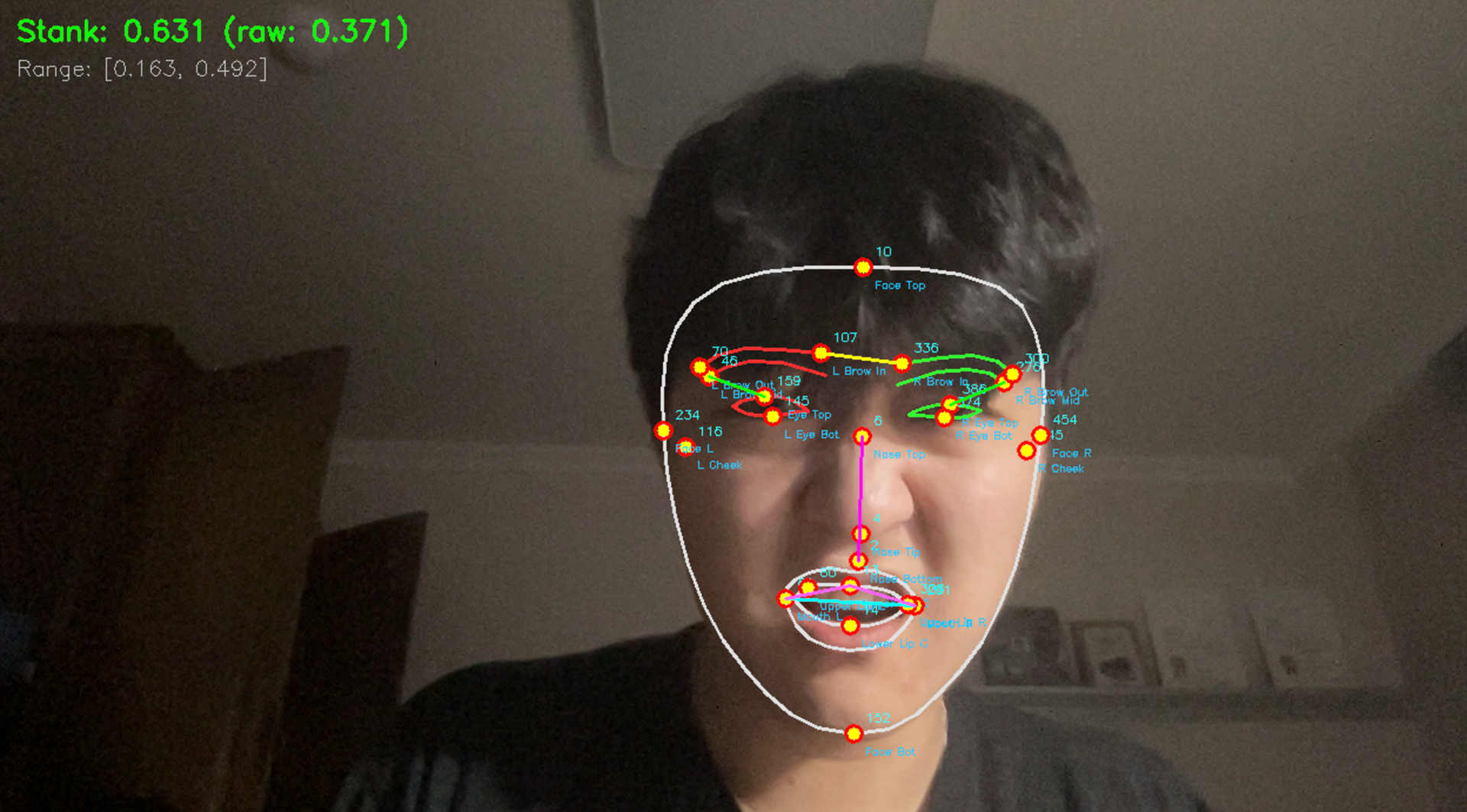
Facial Expression no. 2: Stank Index=0.631
The normalized features are mapped to perceptually meaningful ranges using empirically chosen thresholds and combined via a weighted sum, with greater emphasis on expressive cues such as eyebrow wrinkling and lip shape. A non-linear scaling function expands mid-range expressivity, making subtle facial changes more responsive. The system then applies adaptive normalization by tracking the minimum and maximum values over time and remapping the output to a stable 0–1 range. The result is a continuous, performer-specific Stank Index suitable for real-time control of sound synthesis, effects, and audiovisual systems via OSC.
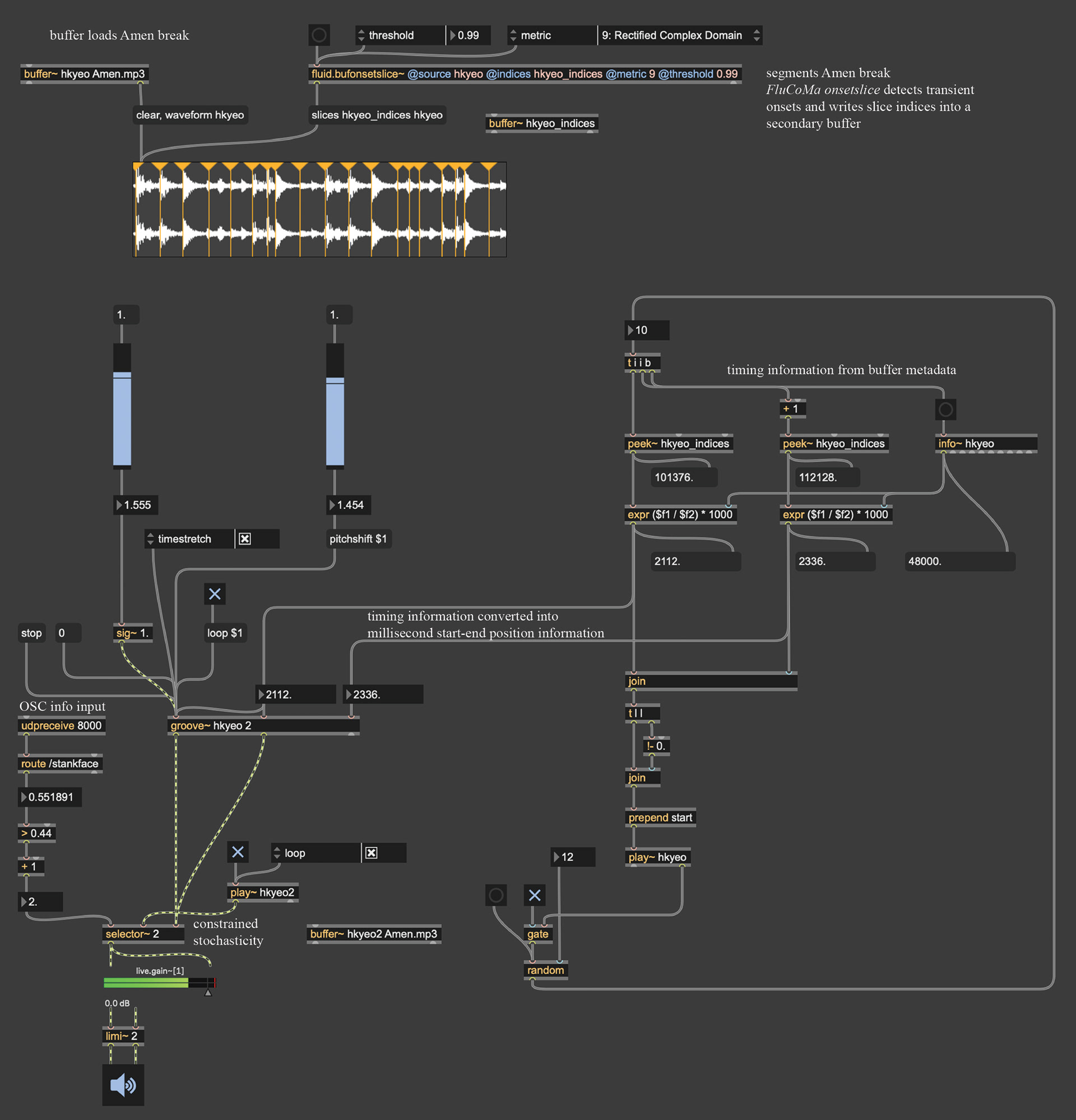
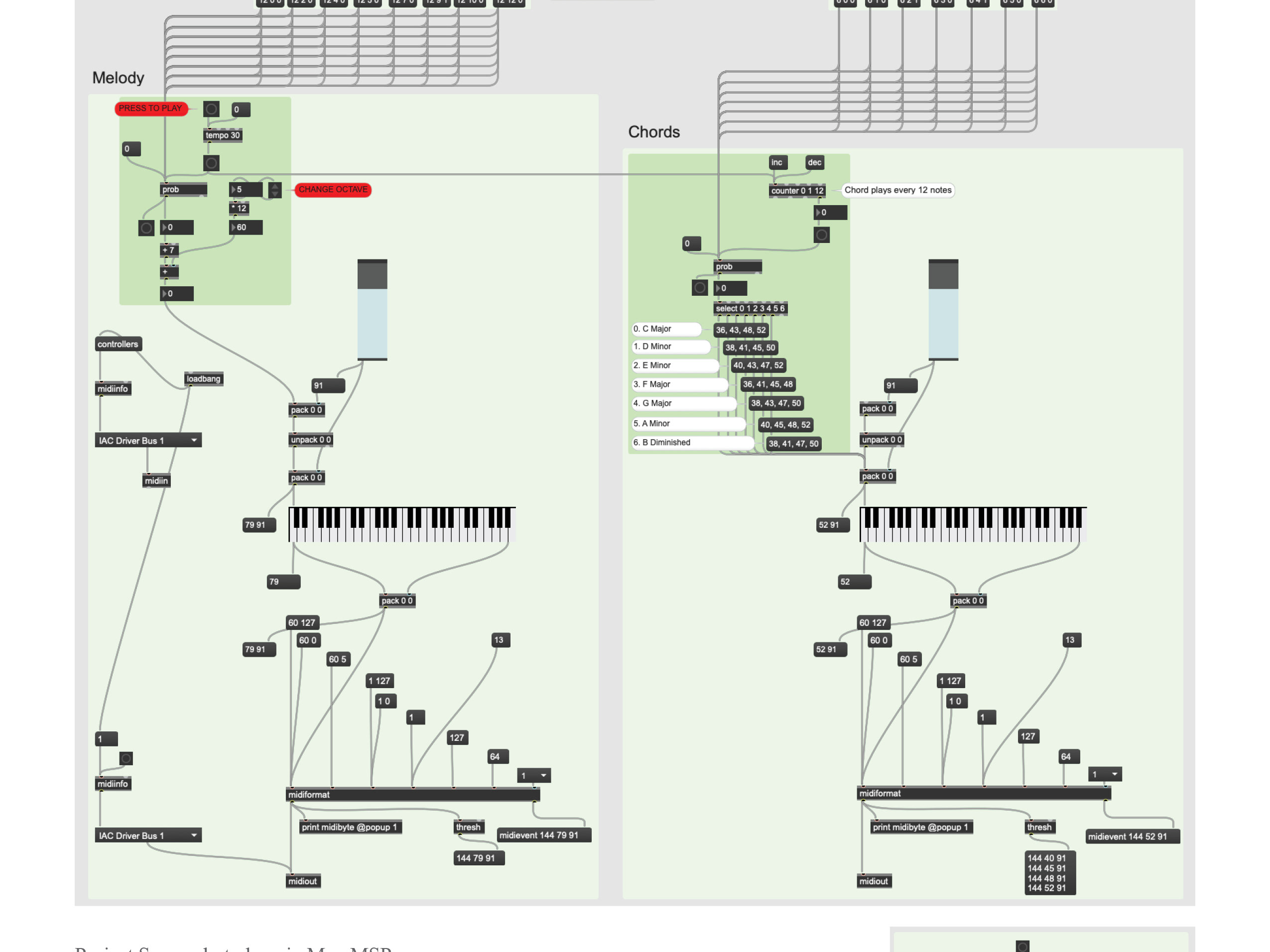
A Max/MSP patch that maps a real-time "Stank Index" to onset-sliced sample playback, dynamically controlling loop position, pitch, and time-stretching through facial gesture input.
This Max patch implements a stankface-driven, slice-based audio playback system that connects gestural intensity to granular control over prerecorded material. An amen break is loaded into a buffer and segmented using Fluid Corpus Manipulation's onsetslice, which detects transient onsets and writes slice indices into a secondary buffer. These indices define musically meaningful micro-phrases that can be accessed nonlinearly rather than through linear playback. Timing information is derived from buffer data (peek~, info~) and converted into start-end position information for playback.
Live control enters the patch via OSC (udpreceive 8000, route /stankface), where the continuous Stank Index modulates playback behavior. This value can be mapped to slice selection, loop activation, pitch shifting, and time stretching within groove~, effectively coupling facial expressivity to rhythmic density and spectral deformation. In the project view above, additional logic modules (gate, random, selector~) introduce constrained stochasticity, allowing the system to oscillate between deterministic gestural control and probabilistic variation. The result is a responsive performance instrument in which embodied facial gestures dynamically reorganize rhythmic structure, playback position, and timbral transformation in real time.
By treating involuntary facial expressions as performative signals, this project situates itself at the intersection of affective computing, embodied music cognition, and interactive media art. It proposes a shift from explicit control interfaces toward systems that respond to how music physically and emotionally impacts the listener, blurring the boundary between performer, audience, and instrument.